Code
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local ![]()
“모든 수는 단위들로 이루어져 있고, 모든 수는 단위들로 나눌 수 있다” - 알 콰리즈미 (780-850), 페르시아의 수학자
이 장에서는 딥러닝의 핵심을 이루는 수학적 개념들을 살펴보겠습니다. 딥러닝 모델은 복잡한 수학적 함수의 조합으로 이루어져 있습니다. 선형대수, 미적분, 확률 및 통계에 대한 깊이 있는 이해는 모델의 동작 원리를 파악하고, 성능을 개선하며, 새로운 모델을 설계하는 데 필수적입니다. 예를 들어, 행렬 연산에 대한 이해는 Convolutional Neural Network (CNN)의 동작 방식을 이해하는 데 중요하며, 미분과 최적화는 모델의 학습 과정을 이해하는 데 핵심적인 역할을 합니다.
이번 장이 어렵게 느껴지는 경우 다음장으로 넘어가도 됩니다. 수시로 되돌아와서 익숙해지는 것이 좋습니다.
선형대수학은 딥러닝의 가장 기초입니다. 행렬 연산부터 고급 최적화 기법에 이르기까지 선형대수는 필수적인 도구입니다. 이 섹션에서는 벡터, 행렬, 텐서 등의 기본 개념부터 시작하여 특이값 분해와 주성분 분석과 같은 고급 주제까지 다룰 것입니다.
벡터와 행렬은 데이터를 표현하고 각 데이터를 변환하는 가장 기본이 되는 연산입니다.
벡터의 기본
벡터는 크기와 방향을 가진 양을 나타내는 수학적 객체입니다. 수학적 정의는 동일합니다. 대신 응용분야 마다 바라보는 관점이 약간 다릅니다.
이러한 다양한 관점을 이해하는 것은 딥러닝에서 벡터를 다룰 때 중요합니다. 딥러닝에서 벡터는 주로 컴퓨터 과학적 관점에서 사용되지만, 수학적 연산과 물리적 직관도 같이 활용합니다.
딥러닝에서 벡터는 주로 데이터의 여러 특성(features)을 동시에 표현하는 데 사용됩니다. 예를 들어, 주택 가격 예측 모델에서 사용되는 5차원 벡터는 다음과 같이 표현할 수 있습니다.
\(\mathbf{v} = \begin{bmatrix} v_1 \ v_2 \ v_3 \ v_4 \ v_5 \end{bmatrix}\)
이 벡터의 각 요소는 주택의 다양한 특성을 나타냅니다. \(v_1\): 주택의 면적 (제곱미터), \(v_2\): 방의 개수, \(v_3\): 주택의 나이 (년), \(v_4\): 주변 학교까지의 거리 (킬로미터), \(v_5\): 범죄율 (백분율)
딥러닝 모델은 이러한 다차원 벡터를 입력으로 주택 가격을 예측할 수 있습니다. 이처럼 벡터는 복잡한 실제 데이터의 여러 특성을 효과적으로 표현하고 처리하는 데 사용됩니다.
넘파이에서 벡터는 손쉽게 생성해서 사용할 수 있습니다.
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your localimport numpy as np
# Vector creation
v = np.array([1, 2, 3])
# Vector magnitude (L2 norm)
magnitude = np.linalg.norm(v)
print(f"Vector magnitude: {magnitude}")
# Vector normalization
normalized_v = v / magnitude
print(f"Normalized vector: {normalized_v}")Vector magnitude: 3.7416573867739413
Normalized vector: [0.26726124 0.53452248 0.80178373]벡터의 개념을 좀 더 깊이 살펴보면, 행벡터와 열벡터의 구분, 그리고 물리학과 공학에서 사용되는 공변벡터와 반변벡터의 개념이 있습니다.
행벡터와 열벡터
벡터는 일반적으로 열벡터를 기본으로 표현합니다. 행벡터는 열벡터의 전치(transpose)로 간주할 수 있습니다. 수학적으로 더 정확히 말하면, 행벡터는 듀얼 벡터 또는 공변벡터(covector)라고 부를 수 있습니다.
열벡터: \(\mathbf{v} = \begin{bmatrix} v_1 \ v_2 \ v_3 \end{bmatrix}\), 행벡터: \(\mathbf{v}^T = [v_1 \quad v_2 \quad v_3]\)
행벡터와 열벡터는 서로 다른 성질을 가지고 있습니다. 행벡터는 열벡터에 대해 선형 함수로 작용하여 스칼라를 생성합니다. 이는 내적 연산으로 표현됩니다.
\[\mathbf{u}^T\mathbf{v} = u_1v_1 + u_2v_2 + u_3v_3\]
공변벡터와 반변벡터
물리학과 공학에서는 공변벡터(covariant vector)와 반변벡터(contravariant vector)의 개념이 중요하게 다뤄집니다. 이는 좌표계 변환에 따른 벡터의 변환 특성을 나타냅니다.
텐서 표기법에서 이러한 구분은 중요합니다. 예를 들어, \(T^i_j\)는 상단 인덱스 \(i\)가 반변성을, 하단 인덱스 \(j\)가 공변성을 나타냅니다. 대표적으로 일반상대론에서 이러한 공변, 반변성은 매우 중요한 개념으로 다뤄집니다.
딥러닝에서의 적용
딥러닝에서는 이러한 공변성과 반변성의 구분이 명시적으로 강조되지 않는 경우가 많습니다. 그 이유는 다음과 같습니다.
그러나 특정 분야, 특히 물리 기반 머신러닝이나 기하학적 딥러닝에서는 이러한 개념이 여전히 중요할 수 있습니다. 예를 들어, 미분기하학을 활용한 딥러닝 모델에서는 공변성과 반변성의 구분이 모델의 설계와 해석에 중요한 역할을 할 수 있습니다.
결론적으로, 딥러닝에서 벡터의 기본 개념은 단순화되어 사용되지만, 더 복잡한 수학적 개념은 고급 모델 설계와 특수한 응용 분야에서 여전히 중요한 역할을 합니다.
선형대수학의 핵심 개념인 벡터 공간(vector space)은 딥러닝에서 데이터를 표현하고 변환하는 기본적인 틀을 제공합니다. 이 딥다이브에서는 벡터 공간의 엄밀한 정의와 관련 개념들을 살펴보고, 딥러닝에서의 응용 예시를 제시합니다.
벡터 공간은 다음 8가지 공리(axiom)를 만족하는 집합 \(V\)와, 덧셈(addition) 및 스칼라 곱(scalar multiplication) 연산으로 구성됩니다. 여기서 \(V\)의 원소를 벡터(vector)라고 부르고, 스칼라(scalar)는 실수(real number) \(\mathbb{R}\) 또는 복소수(complex number) \(\mathbb{C}\) 집합의 원소입니다. (딥러닝에서는 주로 실수를 사용합니다.)
벡터 덧셈 (Vector Addition): \(V\)의 임의의 두 원소 \(\mathbf{u}, \mathbf{v}\)에 대해, \(\mathbf{u} + \mathbf{v}\)도 \(V\)의 원소입니다. (덧셈에 대해 닫혀있다, closed under addition)
스칼라 곱 (Scalar Multiplication): \(V\)의 임의의 원소 \(\mathbf{u}\)와 스칼라 \(c\)에 대해, \(c\mathbf{u}\)도 \(V\)의 원소입니다. (스칼라 곱에 대해 닫혀있다, closed under scalar multiplication)
벡터 덧셈과 스칼라 곱은 다음 8가지 공리를 만족해야 합니다. (\(\mathbf{u}, \mathbf{v}, \mathbf{w} \in V\), \(c, d\): 스칼라)
예시:
벡터 공간 \(V\)의 부분 집합 \(W\)가 다음 조건을 만족하면 \(W\)를 \(V\)의 부분 공간이라고 합니다.
즉, 부분 공간은 벡터 공간의 부분 집합이면서, 그 자체로 벡터 공간의 성질을 만족하는 것입니다.
벡터 공간 \(V\)의 벡터 \(\mathbf{v}_1, \mathbf{v}_2, ..., \mathbf{v}_k\)와 스칼라 \(c_1, c_2, ..., c_k\)에 대해, 다음 형태의 식을 선형 결합이라고 합니다.
\(c_1\mathbf{v}_1 + c_2\mathbf{v}_2 + ... + c_k\mathbf{v}_k\)
벡터들의 집합 {\(\mathbf{v}_1, \mathbf{v}_2, ..., \mathbf{v}_k\)}이 다음 조건을 만족하면 선형 독립(linearly independent)이라고 합니다.
\(c_1\mathbf{v}_1 + c_2\mathbf{v}_2 + ... + c_k\mathbf{v}_k = \mathbf{0}\) 이면, 반드시 \(c_1 = c_2 = ... = c_k = 0\)
위 조건을 만족하지 않으면(즉, 모두 0이 아닌 스칼라 \(c_1, ..., c_k\)가 존재하여 위 식을 만족시키면), 이 벡터들의 집합은 선형 종속(linearly dependent)이라고 합니다.
직관적인 의미:
핵심: 주어진 벡터 공간의 기저는 유일하지 않지만, 모든 기저는 동일한 개수의 벡터를 가집니다.
벡터들의 집합 {\(\mathbf{v}_1, \mathbf{v}_2, ..., \mathbf{v}_k\)}의 span은 이 벡터들의 모든 가능한 선형 결합의 집합입니다.
span{\(\mathbf{v}_1, \mathbf{v}_2, ..., \mathbf{v}_k\)} = {\(c_1\mathbf{v}_1 + c_2\mathbf{v}_2 + ... + c_k\mathbf{v}_k\) | \(c_1, c_2, ..., c_k\)는 스칼라}
즉, 주어진 벡터들을 사용하여 만들 수 있는 모든 벡터의 집합입니다. Span은 항상 부분 공간이 됩니다.
벡터의 크기(magnitude)나 두 벡터 사이의 거리(distance)를 측정하는 것은 딥러닝에서 매우 중요합니다. 손실 함수, 정규화(regularization), 유사도 측정 등 다양한 곳에 활용됩니다.
벡터 \(\mathbf{x} = [x_1, x_2, ..., x_n]\)의 Lp-norm은 다음과 같이 정의됩니다 (\(p \ge 1\)).
\(||\mathbf{x}||_p = \left( \sum_{i=1}^{n} |x_i|^p \right)^{1/p}\)
두 벡터 \(\mathbf{x}\)와 \(\mathbf{y}\) 사이의 거리는 일반적으로 두 벡터의 차이의 노름으로 정의됩니다.
\(d(\mathbf{x}, \mathbf{y}) = ||\mathbf{x} - \mathbf{y}||\)
딥러닝에서의 활용 예시:
참고: 딥러닝에서는 “거리”와 “유사도(similarity)”를 구분하는 것이 중요합니다. 거리는 작을수록 유사도가 높고, 유사도는 클수록 가깝습니다. 코사인 유사도(cosine similarity)는 딥러닝에서 자주 사용되는 유사도 측정 방법 중 하나입니다.
아핀 공간(Affine Space)은 선형대수학의 벡터 공간(Vector Space) 개념을 일반화한 것으로, 기하학적 관점에서 딥러닝 모델을 이해하는 데 유용한 도구입니다. 특히, 아핀 변환(Affine Transformation)은 딥러닝에서 자주 사용되는 선형 변환에 편향(bias)을 추가한 형태를 나타냅니다.
아핀 공간은 (점들의 집합, 벡터 공간, 점과 벡터의 덧셈)의 세 요소로 구성된 구조입니다. 좀 더 구체적으로,
이 덧셈 연산은 다음 두 가지 성질을 만족해야 합니다.
중요한 특징
아핀 공간 \(\mathcal{A}\)의 점 \(P_1, P_2, ..., P_k\)와 스칼라 \(c_1, c_2, ..., c_k\)가 주어졌을 때, 다음 형태의 식을 아핀 결합이라고 합니다.
\(c_1P_1 + c_2P_2 + ... + c_kP_k\) (단, \(c_1 + c_2 + ... + c_k = 1\))
중요: 일반적인 선형 결합과 달리, 아핀 결합은 계수들의 합이 1이어야 합니다. 이 조건은 아핀 공간의 “원점이 없다”는 성질을 반영합니다.
아핀 변환은 아핀 공간에서 아핀 공간으로의 함수로, 선형 변환과 평행 이동(translation)의 조합으로 표현됩니다. 즉, 아핀 변환은 선형 변환과 편향(bias)을 포함합니다.
\(f(P) = T(P) + \mathbf{b}\)
행렬 표현:
아핀 변환은 확장된 행렬(augmented matrix)을 사용하여 표현할 수 있습니다. \(n\)차원 아핀 공간에서 \(n+1\)차원 벡터를 사용하면, 아핀 변환을 \((n+1) \times (n+1)\) 행렬로 나타낼 수 있습니다.
\(\begin{bmatrix} \mathbf{y} \\ 1 \end{bmatrix} = \begin{bmatrix} \mathbf{A} & \mathbf{b} \\ \mathbf{0}^T & 1 \end{bmatrix} \begin{bmatrix} \mathbf{x} \\ 1 \end{bmatrix}\)
최근 딥러닝 연구에서는 계산 효율성, 모델 해석 가능성, 또는 특정 이론적 배경을 바탕으로 편향(bias) 항을 제거한 모델들이 제안되기도 합니다.
Bias를 제거하는 이유
주의: bias를 제거하는 것이 항상 성능 향상을 보장하는 것은 아닙니다. 문제의 특성, 모델의 구조, 데이터의 양 등에 따라 bias의 유무가 성능에 미치는 영향은 달라질 수 있습니다.
아핀 공간과 아핀 변환의 개념은 딥러닝 모델의 기하학적 해석, 일반화 성능 분석, 새로운 아키텍처 설계 등에 활용될 수 있습니다.
텐서, 벡터, 행렬과 관련된 용어들은 수학, 물리학, 컴퓨터 과학 분야에서 약간씩 다르게 사용되어 혼란을 야기할 수 있습니다. 이러한 혼란을 피하기 위해 주요 개념들을 정리해보겠습니다. 텐서의 랭크와 차원에 대해 먼저 살펴보겠습니다. 텐서의 랭크는 텐서가 가진 인덱스의 개수를 의미합니다. 예를 들어, 스칼라는 랭크 0 텐서, 벡터는 랭크 1 텐서, 행렬은 랭크 2 텐서로 분류됩니다. 3차원 이상의 텐서는 일반적으로 그냥 텐서라고 부릅니다.
“차원”이라는 용어는 두 가지 의미로 사용될 수 있어 주의가 필요합니다. 첫 번째로, 텐서의 랭크와 동일한 의미로 사용되는 경우가 있습니다. 이 경우 벡터를 1차원 텐서, 행렬을 2차원 텐서라고 부르게 됩니다. 두 번째로, 배열의 길이 또는 크기를 나타내는 데 사용되기도 합니다. 예를 들어, 벡터 \(\mathbf{a} = [1, 2, 3, 4]\)의 차원이 4라고 표현하는 경우가 이에 해당합니다.
분야별로 용어 사용의 차이를 아는 것도 중요합니다. 물리학에서는 요소의 개수가 물리적 의미를 가지므로 더 엄격하게 사용하는 경향이 있습니다. 반면 컴퓨터 과학에서는 벡터, 행렬, 텐서를 주로 숫자의 배열로 취급하며, “차원”이라는 용어를 데이터의 개수와 인덱스의 개수 모두를 지칭하는 데 혼용하는 경향이 있습니다.
이러한 용어 사용의 차이로 인한 혼란을 피하기 위해서는 몇 가지 주의해야 합니다. 용어의 의미는 맥락에 따라 달라질 수 있으므로 주의 깊게 해석해야 합니다. 논문이나 책에서 어떤 의미로 “차원”을 사용하는지 명확히 구분할 필요가 있습니다. 특히 딥러닝 분야에서는 텐서의 랭크와 배열의 크기를 모두 “차원”으로 표현하는 경우가 많으므로 일관된 해석이 중요합니다.
딥러닝 프레임워크에서는 텐서의 형태(shape)를 나타내는 데 ‘차원(dimension)’ 또는 ’축(axis)’이라는 용어를 사용합니다. 예를 들어, PyTorch에서는 tensor.shape 또는 tensor.size()를 통해 텐서의 각 차원의 크기를 확인할 수 있습니다. 이 책에서는 텐서의 랭크(rank)는 ’차원’으로, 배열의 길이/크기는 shape의 각 요소값 혹은 차원으로 표현하겠습니다.
딥러닝 훈련에 필요한 수학을 살펴보도록 하겠습니다. 신경망의 핵심 연산인 선형변환은 순방향 계산에서 매우 간단하게 표현됩니다. 이 섹션에서는 활성화 함수를 통과하기 전까지의 기본적인 선형 연산에 초점을 맞추겠습니다.
순방향 연산의 기본 형태는 다음과 같습니다.
\[\boldsymbol y = \boldsymbol x \boldsymbol W + \boldsymbol b\]
여기서 \(\boldsymbol x\)는 입력, \(\boldsymbol W\)는 가중치, \(\boldsymbol b\)는 편향, 그리고 \(\boldsymbol y\)는 출력을 나타냅니다. 신경망 수학에서는 입력과 출력을 벡터로, 가중치를 행렬로 표현하는 경우가 많습니다. 편향(\(\boldsymbol b\))은 때로 스칼라값으로 표현되기도 하지만, 정확히는 출력과 동일한 형태인 벡터로 표현해야 합니다.
행렬과 선형변환
행렬은 선형변환을 표현하는 강력한 도구입니다. 선형변환은 벡터 공간의 한 점을 다른 점으로 매핑하는 과정으로, 이는 전체 공간의 변형으로 볼 수 있습니다. 이러한 개념을 시각적으로 이해하는 데 도움이 되는 자료로 3Blue1Brown의 “Linear transformations and matrices” 영상[1]을 추천합니다. 이 영상은 선형대수학의 기본 개념을 직관적으로 설명하며, 행렬이 어떻게 공간을 변형시키는지 명확하게 보여줍니다.
입력 데이터 \(\boldsymbol x\)를 벡터로 표현할 때, 이는 단일 데이터 포인트를 의미하며 벡터의 길이는 특성의 개수가 됩니다. 그러나 실제 훈련 과정에서는 보통 여러 데이터를 한 번에 처리합니다. 이 경우 입력은 (n, m) 형태의 행렬 \(\boldsymbol X\)가 되며, 여기서 n은 데이터의 개수, m은 특성의 개수를 나타냅니다.
실제 딥러닝 모델에서는 입력 데이터가 2차원 행렬을 넘어 더 높은 차원의 텐서 형태를 가질 수 있습니다.
이러한 고차원 데이터를 처리하기 위해 신경망은 다양한 형태의 선형 및 비선형 변환을 사용합니다. 선형변환의 역방향 전파 과정에서는 그래디언트를 계산하고 이를 역순으로 각 층에 전달하여 파라미터를 업데이트합니다. 이 과정은 복잡할 수 있지만, 자동 미분 도구를 통해 효율적으로 수행됩니다. 선형변환은 딥러닝 모델의 기본 구성 요소이지만, 실제 모델의 성능은 비선형 활성화 함수와의 조합을 통해 얻어집니다. 다음 섹션에서는 이러한 비선형성이 어떻게 모델의 표현력을 증가시키는지 살펴보겠습니다.
# if in Colab, plase don't run this and below code. just see the result video bleow the following cell.
#from manim import * %%manim -qh -v WARNING LinearTransformations
from manim import *
from manim import config
class LinearTransformations(ThreeDScene):
def construct(self):
self.set_camera_orientation(phi=75 * DEGREES, theta=-45 * DEGREES)
axes = ThreeDAxes(x_range=[-6, 6, 1], y_range=[-6, 6, 1], z_range=[-6, 6, 1], x_length=10, y_length=10, z_length=10).set_color(GRAY)
self.add(axes)
# --- 3D Linear Transformation (Rotation and Shear) ---
title = Text("3D Linear Transformations", color=BLACK).to_edge(UP)
self.play(Write(title))
self.wait(1)
# 1. Rotation around Z-axis
text_rotation = Text("Rotation around Z-axis", color=BLUE).scale(0.7).next_to(title, DOWN, buff=0.5)
self.play(Write(text_rotation))
cube = Cube(side_length=2, fill_color=BLUE, fill_opacity=0.5, stroke_color=WHITE, stroke_width=1)
self.play(Create(cube))
self.play(Rotate(cube, angle=PI/2, axis=OUT, about_point=ORIGIN), run_time=2)
self.wait(1)
self.play(FadeOut(text_rotation))
# 2. Shear
text_shear = Text("Shear Transformation", color=GREEN).scale(0.7).next_to(title, DOWN, buff=0.5)
self.play(Write(text_shear))
# Define the shear transformation matrix. This shears in x relative to y, and in y relative to x.
shear_matrix = np.array([
[1, 0.5, 0],
[0.5, 1, 0],
[0, 0, 1]
])
self.play(
cube.animate.apply_matrix(shear_matrix),
run_time=2,
)
self.wait(1)
# Add transformed axes to visualize the shear
transformed_axes = axes.copy().apply_matrix(shear_matrix)
self.play(Create(transformed_axes), run_time=1)
self.wait(1)
self.play(FadeOut(cube), FadeOut(transformed_axes), FadeOut(text_shear))
# --- 2D to 3D Transformation (Paraboloid) ---
text_2d_to_3d = Text("2D to 3D: Paraboloid", color=MAROON).scale(0.7).next_to(title, DOWN, buff=0.5)
self.play(Write(text_2d_to_3d))
square = Square(side_length=4, fill_color=MAROON, fill_opacity=0.5, stroke_color=WHITE, stroke_width=1)
self.play(Create(square))
def paraboloid(point): # Function for the transformation
x, y, _ = point
return [x, y, 0.2 * (x**2 + y**2)] # Adjust scaling factor (0.2) as needed
paraboloid_surface = always_redraw(lambda: Surface(
lambda u, v: axes.c2p(*paraboloid(axes.p2c(np.array([u,v,0])))),
u_range=[-2, 2],
v_range=[-2, 2],
resolution=(15, 15), # Added for smoothness
fill_color=MAROON,
fill_opacity=0.7,
stroke_color=WHITE,
stroke_width=0.5
).set_shade_in_3d(True))
self.play(
Transform(square, paraboloid_surface),
run_time=3,
)
self.wait(2)
self.play(FadeOut(square), FadeOut(text_2d_to_3d))
# --- 3D to 2D Transformation (Projection) ---
text_3d_to_2d = Text("3D to 2D: Projection", color=PURPLE).scale(0.7).next_to(title, DOWN, buff=0.5)
self.play(Write(text_3d_to_2d))
sphere = Sphere(radius=1.5, fill_color=PURPLE, fill_opacity=0.7, stroke_color=WHITE, stroke_width=1, resolution=(20,20)).set_shade_in_3d(True)
self.play(Create(sphere))
def project_to_2d(mob, alpha):
for p in mob.points:
p[2] *= (1-alpha)
self.play(
UpdateFromAlphaFunc(sphere, project_to_2d),
run_time=2
)
self.wait(1)
# Show a circle representing the final projection
circle = Circle(radius=1.5, color=PURPLE, fill_opacity=0.7, stroke_color = WHITE, stroke_width=1)
self.add(circle)
self.wait(1)
self.play(FadeOut(sphere), FadeOut(text_3d_to_2d), FadeOut(circle), FadeOut(title))
self.wait(1)
import logging
logging.getLogger("manim").setLevel(logging.WARNING)
if __name__ == "__main__":
config.video_dir = "./"
scene = LinearTransformations()
scene.render()도전과제: 어떻게 하면 다차원 데이터를 효율적으로 표현하고 연산할 수 있을까?
연구자의 고뇌: 딥러닝 초기, 연구자들은 이미지, 텍스트, 오디오 등 다양한 형태의 데이터를 다뤄야 했습니다. 이러한 데이터는 단순한 벡터나 행렬로 표현하기 어려웠고, 복잡한 데이터 구조를 효과적으로 처리할 수 있는 방법이 필요했습니다. 또한, 대규모 데이터를 빠르게 처리하기 위한 효율적인 연산 방법도 중요한 과제였습니다.
텐서는 딥러닝에서 데이터와 모델 파라미터를 표현하는 기본적인 수학적 객체입니다. 스칼라, 벡터, 행렬을 일반화한 개념으로, 다차원 배열로 생각할 수 있습니다. 텐서는 그 차원(dimension, rank) 에 따라 다음과 같이 분류됩니다.
딥러닝에서는 주로 다음과 같은 형태의 텐서를 다룹니다.
신경망의 기본적인 선형변환은 다음과 같습니다.
\(y_j = \sum\limits_{i} x_i w_{ij} + b_j\)
여기서 \(i\)는 입력의 인덱스, \(j\)는 출력의 인덱스입니다. 이를 벡터와 행렬 형태로 표현하면 다음과 같습니다.
\(\boldsymbol x = \begin{bmatrix}x_{1} & x_{2} & \cdots & x_{i} \end{bmatrix}\)
\(\boldsymbol W = \begin{bmatrix} w_{11} & \cdots & w_{1j} \ \vdots & \ddots & \vdots \ w_{i1} & \cdots & w_{ij} \end{bmatrix}\)
\(\boldsymbol b = \begin{bmatrix}b_{1} & b_{2} & \cdots & b_{j} \end{bmatrix}\)
\(\boldsymbol y = \boldsymbol x \boldsymbol W + \boldsymbol b\)
텐서 연산의 주요 특징은 다음과 같습니다.
브로드캐스팅: 크기가 다른 텐서 간의 연산을 가능하게 합니다.
차원 축소: sum(), mean() 등의 연산으로 텐서의 특정 차원을 축소할 수 있습니다.
재형성(reshape): 텐서의 형태를 변경하여 다른 차원의 텐서로 변환할 수 있습니다.
신경망 학습에서 가장 중요한 연산 중 하나는 그래디언트 계산입니다. 주요 그래디언트 계산은 다음과 같습니다.
입력에 대한 그래디언트: \(\frac{\partial \boldsymbol y}{\partial \boldsymbol{x}}\)
가중치에 대한 그래디언트: \(\frac{\partial \boldsymbol y}{\partial \boldsymbol W}\)
이러한 그래디언트는 각각 입력과 가중치의 변화에 따른 출력의 변화를 나타내며, 역전파 알고리즘의 핵심입니다.
텐서 연산은 현대 딥러닝의 근간을 이루며, GPU를 활용한 고도의 병렬 처리를 통해 대규모 모델의 효율적인 학습과 추론을 가능케 합니다. 또한 텐서 연산의 자동 미분(automatic differentiation)은 효율적인 그래디언트 계산을 가능하게 하여 현대 딥러닝 연구의 주요한 돌파구가 되었습니다. 이는 단순한 수치 계산을 넘어, 모델의 구조와 학습 과정 자체를 프로그래밍 가능한 대상으로 만들었습니다. 텐서 연산의 실제적 예는 3장 파이토치에서 추가적으로 살펴보겠습니다.
특이값 분해(Singular Value Decomposition, SVD)와 주성분 분석(Principal Component Analysis, PCA)은 고차원 데이터의 차원을 축소하고, 데이터에 내재된 주요 특징을 추출하는 데 사용되는 강력한 수학적 도구입니다.
SVD는 임의의 \(m \times n\) 행렬 \(\mathbf{A}\)를 다음과 같이 세 행렬의 곱으로 분해하는 방법입니다.
\(\mathbf{A} = \mathbf{U\Sigma V^T}\)
여기서,
핵심 아이디어:
딥러닝에서의 활용:
모델 압축: 신경망의 가중치 행렬에 SVD를 적용하여 저차원 행렬로 근사하면, 모델의 크기를 줄이고 추론 속도를 향상시킬 수 있습니다. 특히, Transformer 기반 언어 모델(예: BERT)에서 임베딩 행렬의 크기를 줄이는 데 효과적입니다.
추천 시스템: SVD를 활용하여 사용자와 아이템 간의 잠재 요인(latent factor)을 추출 할 수 있습니다.
PCA는 데이터의 분산을 최대화하는 방향(주성분, principal component)을 찾아 데이터를 저차원 공간에 투영하는 방법입니다. SVD와 밀접하게 관련되어 있으며, 데이터의 공분산 행렬(covariance matrix)에 대한 고유값 분해(eigenvalue decomposition)를 통해 주성분을 찾습니다.
PCA 단계:
딥러닝에서의 활용:
SVD vs. PCA
SVD와 PCA는 딥러닝에서 데이터를 효율적으로 표현하고, 모델의 성능을 향상시키는 데 중요한 역할을 하는 수학적 도구입니다.
from dldna.chapter_02.pca import visualize_pca
visualize_pca()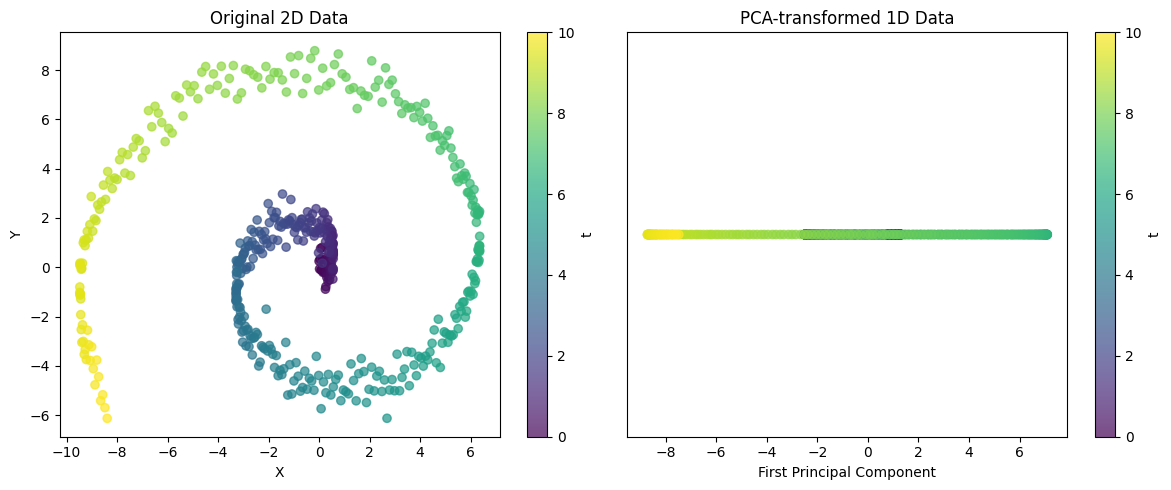
Explained variance ratio: 0.5705이 예제는 복잡한 2차원 구조를 1차원으로 투영하는 PCA의 능력을 보여줍니다. 나선형 데이터의 경우, 단일 주성분으로는 모든 변동성을 캡처할 수 없지만, 데이터의 주요 트렌드를 포착할 수 있습니다. 설명된 분산 비율을 통해 이 1차원 표현이 원본 데이터의 구조를 얼마나 잘 보존하는지 평가할 수 있습니다
이 기법들은 복잡한 데이터에서 중요한 패턴을 추출하는 강력한 도구입니다.
SVD와 PCA는 고차원 데이터에서 중요한 패턴을 추출하고, 복잡한 데이터 구조를 단순화하는 강력한 도구입니다.
도전과제: 어떻게 복잡하게 중첩된 함수의 미분을 효율적으로 계산할 수 있을까?
연구자의 고뇌: 초기 딥러닝 연구자들은 신경망의 가중치를 업데이트하기 위해 역전파 알고리즘을 사용해야 했습니다. 하지만 신경망은 여러 층의 함수가 복잡하게 연결된 구조이기 때문에, 각 가중치에 대한 손실 함수의 미분을 계산하는 것은 매우 어려운 문제였습니다. 특히, 층이 깊어질수록 계산량이 기하급수적으로 증가하여 학습이 비효율적이었습니다.
딥러닝에서 사용하는 가장 중요한 미적분 규칙은 체인룰(chain rule)입니다. 체인룰은 복합 함수의 미분을 구성 함수들의 미분의 곱으로 표현할 수 있게 해주는 강력하고 우아한 규칙입니다. 체인룰을 시각화하면 그 개념을 더 쉽게 이해할 수 있습니다. 예를 들어, \(z\)가 \(x\)와 \(y\)의 함수이고, \(x\)와 \(y\)가 각각 \(s\)와 \(t\)의 함수라고 가정해 봅시다. 이 관계를 트리 다이어그램으로 나타낼 수 있습니다.
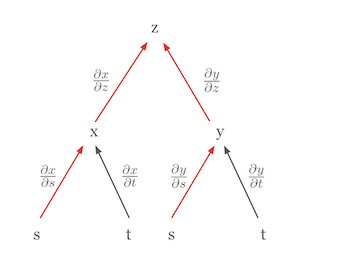
이 다이어그램에서, \(z\)의 \(s\)에 대한 편미분 \(\frac{\partial z}{\partial s}\)는 \(z\)에서 \(s\)로 가는 모든 경로를 따라 편미분들의 곱을 더한 것과 같습니다.
\(\frac{\partial z}{\partial s} = \frac{\partial z}{\partial x} \frac{\partial x}{\partial s} + \frac{\partial z}{\partial y} \frac{\partial y}{\partial s}\)
이 공식에서
다른 경우로 체인룰을 이용한 전미분 표현을 살펴봅시다. \(z\)가 상호 독립적인 변수들의 함수일 때를 고려해 봅시다. 이 경우, 체인룰은 전미분의 형태로 간소화됩니다. 예를 들어, \(z = f(x, y)\)이고 \(x = g(s)\), \(y = h(t)\)일 때, \(s\)와 \(t\)가 서로 독립적이라면, \(z\)의 전미분은 다음과 같이 표현됩니다.
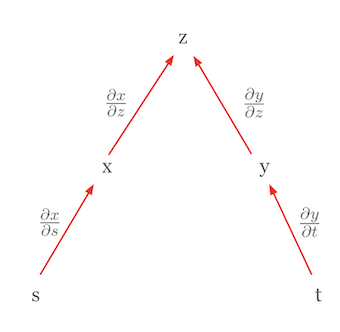
\(dz = \frac{\partial z}{\partial x}dx + \frac{\partial z}{\partial y}dy\)
여기서 \(dx = \frac{\partial x}{\partial s}ds\)와 \(dy = \frac{\partial y}{\partial t}dt\)이므로, 최종적으로 다음과 같은 형태가 됩니다.
\(dz = \frac{\partial z}{\partial x}\frac{\partial x}{\partial s}ds + \frac{\partial z}{\partial y}\frac{\partial y}{\partial t}dt\)
이 식은 체인룰의 형태와 유사해 보이지만, 실제로는 전미분을 나타냅니다. 여기서 중요한 점은 \(s\)와 \(t\)가 독립적이기 때문에, \(\frac{\partial x}{\partial t}\)와 \(\frac{\partial y}{\partial s}\)가 0이 된다는 것입니다. 이러한 형태는 전미분입니다. 전미분은 모든 독립 변수의 변화가 함수값에 미치는 총 영향을 나타내며, 각 변수에 대한 편미분의 합으로 표현됩니다.
체인룰의 이런 구조는 복잡한 함수의 미분을 더 간단한 부분들로 분해할 수 있게 해줍니다. 이는 특히 딥러닝에서 중요한데, 신경망은 여러 층의 함수들이 중첩된 구조이기 때문입니다. 트리 다이어그램을 사용하면 더 복잡한 상황에서도 체인룰을 쉽게 적용할 수 있습니다. 종속 변수에서 시작하여 중간 변수들을 거쳐 독립 변수들로 이어지는 모든 경로를 찾고, 각 경로를 따라 편미분들을 곱한 다음, 이 결과들을 모두 더하면 됩니다.
체인룰은 딥러닝에서 역전파 알고리즘의 수학적 기반입니다. 복잡한 신경망 모델의 가중치를 효율적으로 업데이트할 수 있게 해주는 근간이 됩니다.
도전 과제: 다양한 형태의 입출력을 갖는 함수에 대한 미분을 어떻게 일반화 할 수 있을까?
연구자의 고뇌: 초창기 딥러닝은 주로 스칼라 함수를 다루었지만, 점차 벡터, 행렬 등 다양한 형태의 입출력을 갖는 함수를 다루게 되었습니다. 이러한 함수들의 미분을 통일된 방식으로 표현하고 계산하는 것은 딥러닝 프레임워크 개발에 필수적인 과제였습니다.
딥러닝에서는 다양한 형태의 입력(스칼라, 벡터, 행렬, 텐서)과 출력(스칼라, 벡터, 행렬, 텐서)을 갖는 함수를 다룹니다. 이에 따라 함수의 미분(도함수) 표현도 달라집니다. 핵심은 이러한 다양한 경우의 미분을 일관성 있게 표현하고, 연쇄 법칙(chain rule)을 적용하여 효율적으로 계산하는 것입니다.
그래디언트(Gradient): 스칼라 함수를 벡터로 미분할 때 사용하는 표현입니다. 입력 벡터의 각 요소에 대한 함수의 편미분을 요소로 갖는 열벡터입니다. 함수의 가장 가파른 상승 방향을 나타냅니다.
야코비안 행렬(Jacobian Matrix): 벡터 함수를 벡터로 미분할 때 사용하는 표현입니다. 출력 벡터의 각 요소를 입력 벡터의 각 요소로 편미분한 값들을 요소로 갖는 행렬입니다.
| 입력 형태 | 출력 형태 | 도함수 표현 | 차원 |
|---|---|---|---|
| 벡터 (\(\mathbf{x}\)) | 벡터 (\(\mathbf{f}\)) | 야코비안 행렬 (\(\mathbf{J} = \frac{\partial \mathbf{f}}{\partial \mathbf{x}}\)) | \(n \times m\) |
| 행렬 (\(\mathbf{X}\)) | 벡터 (\(\mathbf{f}\)) | 3차원 텐서 (일반적으로 잘 다루지 않음) | - |
| 벡터 (\(\mathbf{x}\)) | 행렬 (\(\mathbf{F}\)) | 3차원 텐서 (일반적으로 잘 다루지 않음) | - |
| 스칼라 (\(x\)) | 벡터 (\(\mathbf{f}\)) | 열벡터 (\(\frac{\partial \mathbf{f}}{\partial x}\)) | \(n \times 1\) |
| 벡터 (\(\mathbf{x}\)) | 스칼라 (\(f\)) | 그래디언트 (\(\nabla f = \frac{\partial f}{\partial \mathbf{x}}\)) | \(m \times 1\) (열벡터) |
| 행렬 (\(\mathbf{X}\)) | 스칼라 (\(f\)) | 행렬 (\(\frac{\partial f}{\partial \mathbf{X}}\)) | \(m \times n\) |
참고:
\(m\): 입력 벡터/행렬의 차원, \(n\): 출력 벡터/행렬의 차원, \(p, q\): 행렬의 행/열 개수
행렬 입력, 벡터/행렬 출력의 경우, 도함수는 3차원 텐서가 됩니다. 딥러닝 프레임워크는 내부적으로 이러한 고차원 텐서 연산을 효율적으로 처리하지만, 일반적으로는 벡터/행렬 입출력에 대한 야코비안/그래디언트 계산이 주를 이룹니다.
이처럼, 그래디언트와 야코비안 행렬의 개념은 딥러닝에서 다양한 형태의 함수에 대한 미분을 일반화하고, 역전파를 통해 효율적으로 모델을 학습시키는 데 필수적인 도구입니다.
정의: 헤시안 행렬은 스칼라 함수(scalar-valued function)의 이계도 함수(second-order partial derivatives)를 행렬 형태로 표현한 것입니다. 즉, 함수 \(f(x_1, x_2, ..., x_n)\)가 주어졌을 때, 헤시안 행렬 \(H\)는 다음과 같이 정의됩니다.
\[ H = \begin{bmatrix} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \\ \frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \end{bmatrix} \]
의미:
신경망 학습의 핵심은 역전파(Backpropagation) 알고리즘입니다. 역전파는 출력층에서 발생한 오차를 입력층 방향으로 전파하면서 각 층의 가중치와 편향을 업데이트하는 효율적인 방법입니다. 이 과정에서 체인룰(Chain Rule)은 복잡한 합성 함수의 미분을 간단한 미분들의 곱으로 표현하여 계산을 가능하게 합니다.
신경망은 여러 층의 함수들이 합성된 형태입니다. 예를 들어, 2층 신경망은 다음과 같이 표현될 수 있습니다.
\(\mathbf{z} = f_1(\mathbf{x}; \mathbf{W_1}, \mathbf{b_1})\) \(\mathbf{y} = f_2(\mathbf{z}; \mathbf{W_2}, \mathbf{b_2})\)
여기서 \(\mathbf{x}\)는 입력, \(\mathbf{z}\)는 첫 번째 층의 출력(두 번째 층의 입력), \(\mathbf{y}\)는 최종 출력, \(\mathbf{W_1}\), \(\mathbf{b_1}\)은 첫 번째 층의 가중치와 편향, \(\mathbf{W_2}\), \(\mathbf{b_2}\)는 두 번째 층의 가중치와 편향입니다.
역전파 과정에서 우리는 손실 함수 \(E\)의 각 파라미터에 대한 그래디언트 (\(\frac{\partial E}{\partial \mathbf{W_1}}\), \(\frac{\partial E}{\partial \mathbf{b_1}}\), \(\frac{\partial E}{\partial \mathbf{W_2}}\), \(\frac{\partial E}{\partial \mathbf{b_2}}\))를 계산해야 합니다. 이때 체인룰을 적용하면 다음과 같이 계산할 수 있습니다.
\(\frac{\partial E}{\partial \mathbf{W_2}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{W_2}}\) \(\frac{\partial E}{\partial \mathbf{b_2}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{b_2}}\) \(\frac{\partial E}{\partial \mathbf{W_1}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{z}} \frac{\partial \mathbf{z}}{\partial \mathbf{W_1}}\) \(\frac{\partial E}{\partial \mathbf{b_1}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{z}} \frac{\partial \mathbf{z}}{\partial \mathbf{b_1}}\)
이처럼 체인룰을 이용하면, 복잡한 신경망의 각 파라미터에 대한 그래디언트를 연쇄적인 미분의 곱으로 분해하여 효율적으로 계산할 수 있습니다. 2.2.4의 이론 딥다이브는 이 과정을 자세히 설명합니다.
이러한 개념들을 바탕으로, 다음 절에서는 구체적인 예시와 함께 역전파 과정에서의 그래디언트 계산 방법을 자세히 살펴보겠습니다.
역전파의 핵심은 손실 함수(Loss Function)의 그래디언트를 계산하여 가중치를 업데이트하는 것입니다. 간단한 선형 변환(\(\mathbf{y} = \mathbf{xW} + \mathbf{b}\))을 예로 들어 역전파 과정을 살펴보겠습니다.
역전파는 출력층에서 계산된 오차를 입력층 방향으로 전파하면서, 각 가중치가 오차에 기여한 만큼 가중치를 업데이트하는 알고리즘입니다. 이 과정에서 각 가중치에 대한 손실 함수의 그래디언트를 계산하는 것이 핵심입니다.
평균 제곱 오차(Mean Squared Error, MSE)를 손실 함수로 사용하면, 출력 \(\mathbf{y}\)에 대한 손실 함수 \(E\)의 그래디언트는 다음과 같습니다.
\(E = \frac{1}{M} \sum_{i=1}^{M} (y_i - \hat{y}_i)^2\)
\(\frac{\partial E}{\partial \mathbf{y}} = \frac{2}{M}(\mathbf{y} - \hat{\mathbf{y}})\)
여기서 \(y_i\)는 실제 값, \(\hat{y}_i\)는 모델의 예측값, \(M\)은 데이터의 개수입니다.
체인룰을 적용하여 가중치 \(\mathbf{W}\)에 대한 손실 함수 \(E\)의 그래디언트를 계산할 수 있습니다.
\(\frac{\partial E}{\partial \mathbf{W}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{W}}\)
\(\mathbf{y} = \mathbf{xW} + \mathbf{b}\) 이므로, \(\frac{\partial \mathbf{y}}{\partial \mathbf{W}} = \mathbf{x}^T\) 입니다.
최종적으로 가중치에 대한 그래디언트는 다음과 같이 표현됩니다.
\(\frac{\partial E}{\partial \mathbf{W}} = \mathbf{x}^T \frac{\partial E}{\partial \mathbf{y}}\)
입력 \(\mathbf{x}\)에 대한 손실 함수 \(E\)의 그래디언트는 이전 층으로 오차를 전파하는 데 사용됩니다.
\(\frac{\partial E}{\partial \mathbf{x}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{x}}\)
\(\mathbf{y} = \mathbf{xW} + \mathbf{b}\) 이므로, \(\frac{\partial \mathbf{y}}{\partial \mathbf{x}} = \mathbf{W}^T\) 입니다.
따라서, 입력에 대한 그래디언트는 다음과 같습니다.
\(\frac{\partial E}{\partial \mathbf{x}} = \frac{\partial E}{\partial \mathbf{y}} \mathbf{W}^T\)
역전파는 다음과 같은 핵심 단계를 통해 이루어집니다.
역전파 알고리즘은 딥러닝 모델 학습의 핵심이며, 이를 통해 복잡한 비선형 함수를 효과적으로 근사할 수 있습니다.
역전파의 핵심은 손실 함수(Loss Function)의 그래디언트를 계산하여 가중치를 업데이트하는 것입니다. 간단한 선형 변환(\(\mathbf{y} = \mathbf{xW} + \mathbf{b}\))을 예로 들어 역전파 과정을 살펴보겠습니다. 여기서는 계산 과정을 최대한 상세하게 풀어서 설명합니다.
신경망 학습의 목표는 손실 함수 \(E\)를 최소화하는 것입니다. 평균 제곱 오차(MSE)를 손실 함수로 사용하는 경우는 다음과 같습니다.
\(E = f(\mathbf{y}) = \frac{1}{M} \sum_{i=1}^{M} (y_i - \hat{y}_i)^2\)
여기서 \(y_i\)는 실제 값, \(\hat{y}_i\)는 예측값, \(M\)은 데이터의 개수(또는 출력 벡터의 차원)입니다.
\(E\)의 \(\mathbf{y}\)에 대한 도함수(derivative)는 다음과 같습니다.
\(\frac{\partial E}{\partial \mathbf{y}} = \frac{2}{M} (\mathbf{y} - \hat{\mathbf{y}})\)
여기서 \(\mathbf{y}\)는 신경망의 출력 벡터, \(\hat{\mathbf{y}}\)는 실제 값(타겟) 벡터입니다. \(y_i\)는 상수(타겟의 각 요소)이므로, \(\mathbf{y}\)에 대한 편미분만 남게 됩니다.
주의: 1장의 예제 코드에서는 \(-\frac{2}{M}\) 항을 사용했는데, 이는 손실 함수 정의에 음수 부호(-)가 포함되어 있었기 때문입니다. 여기서는 일반적인 MSE 정의를 사용하므로 양수 \(\frac{2}{M}\)을 사용합니다. 실제 학습에서는 학습률(learning rate)을 곱하므로 이 상수의 절대적인 크기는 중요하지 않습니다.
이제, 가중치 \(\mathbf{W}\)에 대한 손실 함수 \(E\)의 그래디언트를 계산해 보겠습니다. \(E = f(\mathbf{y})\)이고 \(\mathbf{y} = \mathbf{xW} + \mathbf{b}\) 입니다. \(\mathbf{x}\)는 입력 벡터, \(\mathbf{W}\)는 가중치 행렬, \(\mathbf{b}\)는 편향 벡터입니다.
계산 그래프:
역전파 과정을 시각적으로 표현하기 위해 계산 그래프를 사용할 수 있습니다. (계산 그래프 그림 삽입)
\(E\)는 스칼라 값이고, 각 \(w_{ij}\) (가중치 행렬 \(\mathbf{W}\)의 각 요소)에 대해 \(E\)의 편미분을 구해야 합니다. \(\mathbf{W}\)는 (입력 차원) x (출력 차원) 크기의 행렬입니다. 예를 들어, 입력이 3차원(\(x_1, x_2, x_3\)), 출력이 2차원(\(y_1, y_2\))이라면, \(\mathbf{W}\)는 3x2 행렬이 됩니다.
\(\frac{\partial E}{\partial \mathbf{W}} = \begin{bmatrix} \frac{\partial E}{\partial w_{11}} & \frac{\partial E}{\partial w_{12}} \\ \frac{\partial E}{\partial w_{21}} & \frac{\partial E}{\partial w_{22}} \\ \frac{\partial E}{\partial w_{31}} & \frac{\partial E}{\partial w_{32}} \end{bmatrix}\)
\(E\)의 \(\mathbf{y}\)에 대한 도함수는 \(\frac{\partial E}{\partial \mathbf{y}} = \begin{bmatrix} \frac{\partial E}{\partial y_1} & \frac{\partial E}{\partial y_2} \end{bmatrix}\) 와 같이 행 벡터로 표현될 수 있습니다. (분자 표기법 사용). 엄밀하게는 그래디언트는 열 벡터로 표현해야 하지만, 여기서는 계산의 편의를 위해 행 벡터를 사용합니다.
체인룰에 의해,
\(\frac{\partial E}{\partial \mathbf{W}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{W}}\)
\(\frac{\partial E}{\partial w_{ij}} = \sum_k \frac{\partial E}{\partial y_k} \frac{\partial y_k}{\partial w_{ij}}\) (여기서 \(k\)는 출력 벡터 \(\mathbf{y}\)의 인덱스)
위 식을 풀어서 쓰면,
\(\frac{\partial E}{\partial \mathbf{W}} = \frac{\partial E}{\partial y_1} \frac{\partial y_1}{\partial \mathbf{W}} + \frac{\partial E}{\partial y_2} \frac{\partial y_2}{\partial \mathbf{W}}\)
이제 \(\frac{\partial y_k}{\partial w_{ij}}\) 를 계산해야 합니다. \(\mathbf{y} = \mathbf{xW} + \mathbf{b}\) 이므로,
\(y_1 = x_1w_{11} + x_2w_{21} + x_3w_{31} + b_1\) \(y_2 = x_1w_{12} + x_2w_{22} + x_3w_{32} + b_2\)
\(\frac{\partial y_1}{\partial w_{ij}} = \begin{bmatrix} \frac{\partial y_1}{\partial w_{11}} & \frac{\partial y_1}{\partial w_{12}} \\ \frac{\partial y_1}{\partial w_{21}} & \frac{\partial y_1}{\partial w_{22}} \\ \frac{\partial y_1}{\partial w_{31}} & \frac{\partial y_1}{\partial w_{32}} \end{bmatrix} = \begin{bmatrix} x_1 & 0 \\ x_2 & 0 \\ x_3 & 0 \end{bmatrix}\)
\(\frac{\partial y_2}{\partial w_{ij}} = \begin{bmatrix} 0 & x_1 \\ 0 & x_2 \\ 0 & x_3 \end{bmatrix}\)
따라서,
\(\frac{\partial E}{\partial \mathbf{W}} = \frac{\partial E}{\partial y_1} \begin{bmatrix} x_1 & 0 \\ x_2 & 0 \\ x_3 & 0 \end{bmatrix} + \frac{\partial E}{\partial y_2} \begin{bmatrix} 0 & x_1 \\ 0 & x_2 \\ 0 & x_3 \end{bmatrix} = \begin{bmatrix} \frac{\partial E}{\partial y_1}x_1 & \frac{\partial E}{\partial y_2}x_1 \\ \frac{\partial E}{\partial y_1}x_2 & \frac{\partial E}{\partial y_2}x_2 \\ \frac{\partial E}{\partial y_1}x_3 & \frac{\partial E}{\partial y_2}x_3 \end{bmatrix} = \begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix} \begin{bmatrix} \frac{\partial E}{\partial y_1} & \frac{\partial E}{\partial y_2} \end{bmatrix} = \mathbf{x}^T \frac{\partial E}{\partial \mathbf{y}}\)
일반화:
입력이 \(1 \times m\) 행 벡터 \(\mathbf{x}\), 출력이 \(1 \times n\) 행 벡터 \(\mathbf{y}\)인 경우, 가중치 \(\mathbf{W}\)는 \(m \times n\) 행렬이 됩니다. 이때,
\(\frac{\partial E}{\partial \mathbf{W}} = \mathbf{x}^T \frac{\partial E}{\partial \mathbf{y}}\)
입력 \(\mathbf{x}\)에 대한 손실 함수 \(E\)의 그래디언트도 마찬가지로 체인룰을 사용하여 계산할 수 있습니다.
\(\frac{\partial E}{\partial \mathbf{x}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{x}}\)
\(\mathbf{y} = \mathbf{xW} + \mathbf{b}\) 이므로, \(\frac{\partial \mathbf{y}}{\partial \mathbf{x}} = \mathbf{W}^T\) 입니다.
따라서,
\(\frac{\partial E}{\partial \mathbf{x}} = \frac{\partial E}{\partial \mathbf{y}} \mathbf{W}^T\)
편향 \(\mathbf{b}\)에 대한 손실 함수의 그래디언트는 다음과 같습니다.
\(\frac{\partial E}{\partial \mathbf{b}} = \frac{\partial E}{\partial \mathbf{y}} \frac{\partial \mathbf{y}}{\partial \mathbf{b}}\)
\(\mathbf{y} = \mathbf{xW} + \mathbf{b}\) 이므로, \(\frac{\partial \mathbf{y}}{\partial \mathbf{b}} = \begin{bmatrix} 1 & 1 & \dots & 1\end{bmatrix}\) (1로만 이루어진 \(1 \times n\) 행벡터)
\(\frac{\partial E}{\partial \mathbf{b}} = \frac{\partial E}{\partial \mathbf{y}}\)
그래디언트의 활용: 이렇게 계산된 그래디언트들은 경사 하강법(Gradient Descent)과 같은 최적화 알고리즘에서 가중치와 편향을 업데이트하는 데 사용됩니다. 각 파라미터는 그래디언트의 반대 방향으로 업데이트되어 손실 함수를 최소화합니다.
표기법: 위 설명에서는 분자 표기법(numerator layout)을 사용하여 그래디언트를 계산했습니다. 분모 표기법(denominator layout)을 사용할 수도 있지만, 결과적으로 동일한 업데이트 규칙을 얻게 됩니다. 중요한 것은 일관된 표기법을 사용하는 것입니다. 이 책에서는 분자 표기법을 사용합니다.
이러한 수학적 과정을 통해 딥러닝 모델은 입력 데이터로부터 출력 데이터로의 복잡한 비선형 변환을 학습할 수 있습니다.
딥러닝은 데이터의 불확실성을 다루는 확률과 통계 이론에 깊이 뿌리를 두고 있습니다. 이 장에서는 확률 분포, 기댓값, 베이즈 정리, 최대 우도 추정 등 핵심 개념을 살펴보겠습니다. 이러한 개념들은 모델의 학습과 추론 과정을 이해하는 데 필수적입니다.
도전 과제: 실제 데이터의 불확실성을 어떻게 수학적으로 모델링 할 수 있을까?
연구자의 고뇌: 초창기 머신러닝 연구자들은 현실 세계의 데이터가 결정론적인(deterministic) 규칙으로 설명될 수 없다는 것을 인지했습니다. 데이터에는 측정 오차, 잡음, 예측 불가능한 변동성이 존재하기 때문입니다. 이러한 불확실성을 정량화하고 모델에 반영하기 위한 수학적 도구가 필요했습니다.
확률 분포는 가능한 모든 결과와 그 발생 확률을 나타냅니다. 이산 확률 분포와 연속 확률 분포로 나눌 수 있습니다.
이산 확률 분포는 확률 변수가 취할 수 있는 값이 유한하거나 셀 수 있는 경우를 다룹니다. 각 가능한 결과에 대해 명확한 확률을 할당할 수 있다는 점이 특징입니다.
수학적으로, 이산 확률 분포는 확률 질량 함수(PMF)로 표현됩니다.
\[P(X = x) = p(x)\]
여기서 p(x)는 X가 값 x를 가질 확률입니다. 주요 성질은 다음과 같습니다.
대표적인 예로는 베르누이 분포, 이항 분포, 포아송 분포가 있습니다.
주사위 던지기의 확률 질량 함수는 다음과 같습니다.
\[P(X = x) = \begin{cases} \frac{1}{6} & \text{if } x \in \{1, 2, 3, 4, 5, 6\} \ 0 & \text{otherwise} \end{cases}\]
이산 확률 분포는 머신러닝과 딥러닝에서 분류 문제, 강화학습, 자연어 처리 등 다양한 분야에서 활용됩니다. 다음은 주사위 던지기를 시뮤레이션 한 결과입니다.
from dldna.chapter_02.statistics import simulate_dice_roll
simulate_dice_roll()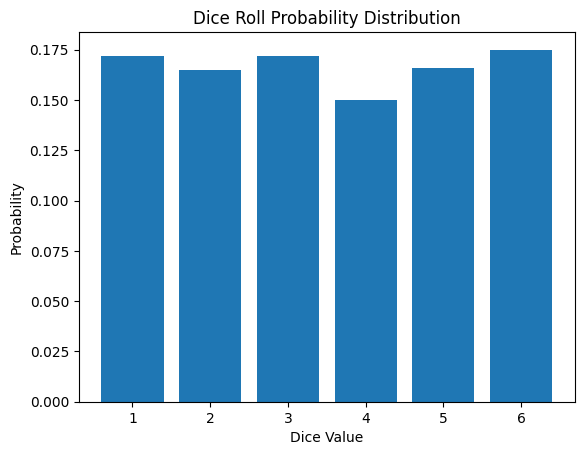
연속 확률 분포는 확률 변수가 연속적인 값을 취할 수 있는 경우를 다룹니다. 이산 확률 분포와 달리, 특정 점에서의 확률은 0이며, 구간에 대한 확률을 다룹니다. 수학적으로, 연속 확률 분포는 확률 밀도 함수(Probability Density Function, PDF)로 표현됩니다.
\[f(x) = \lim_{\Delta x \to 0} \frac{P(x < X \leq x + \Delta x)}{\Delta x}\]
여기서 f(x)는 x 근처에서의 확률 밀도를 나타냅니다. 주요 성질은 다음과 같습니다.
대표적인 예로는 정규 분포, 지수 분포, 감마 분포가 있습니다.
정규 분포의 확률 밀도 함수는 다음과 같습니다.
\[f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]
여기서 μ는 평균, σ는 표준편차입니다.
연속 확률 분포는 회귀 문제, 신호 처리, 시계열 분석 등 다양한 머신러닝과 딥러닝 응용 분야에서 중요하게 사용됩니다.
from dldna.chapter_02.statistics import plot_normal_distribution
plot_normal_distribution()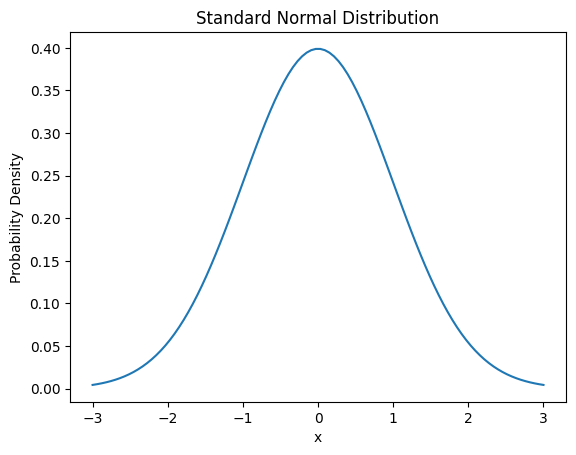
기댓값은 확률 분포의 중심 경향을 나타내는 중요한 개념입니다. 이는 확률 변수의 가능한 모든 값에 대한 가중 평균으로 해석할 수 있습니다. 이산 확률 분포의 경우, 기댓값은 다음과 같이 계산됩니다.
\[E[X] = \sum_{i} x_i P(X = x_i)\]
여기서 \(x_i\)는 확률 변수 X의 가능한 값이고, \(P(X = x_i)\)는 그 값의 확률입니다. 연속 확률 분포의 경우, 기댓값은 적분을 통해 계산됩니다.
\[E[X] = \int_{-\infty}^{\infty} x f(x) dx\]
여기서 \(f(x)\)는 확률 밀도 함수입니다. 기댓값은 다음과 같은 중요한 성질을 가집니다.
딥러닝에서 기댓값은 손실 함수의 최소화나 모델 파라미터의 추정에 핵심적으로 사용됩니다. 예를 들어, 평균 제곱 오차(MSE)는 다음과 같이 정의됩니다.
\[MSE = E[(Y - \hat{Y})^2]\]
여기서 \(Y\)는 실제값, \(\hat{Y}\)는 예측값입니다.
기댓값의 개념은 확률적 경사 하강법(Stochastic Gradient Descent)과 같은 최적화 알고리즘의 이론적 기반을 제공하며, 강화학습에서의 가치 함수 추정에도 중요하게 활용됩니다.
from dldna.chapter_02.statistics import calculate_dice_expected_value
calculate_dice_expected_value()Expected value of dice roll: 3.5이러한 확률과 통계의 기본 개념들은 딥러닝 모델의 설계, 학습, 평가 과정에서 핵심적인 역할을 합니다. 다음 섹션에서는 이를 바탕으로 베이즈 정리와 최대 우도 추정에 대해 알아보겠습니다.
도전과제: 어떻게 제한된 데이터를 가지고 모델의 파라미터를 가장 잘 추정할 수 있을까?
연구자의 고뇌: 초기 통계학자들과 머신러닝 연구자들은 종종 제한된 데이터만을 가지고 모델을 만들어야 하는 상황에 직면했습니다. 데이터가 충분하지 않은 상황에서 모델의 파라미터를 정확하게 추정하는 것은 매우 어려운 문제였습니다. 단순히 데이터에만 의존하는 것이 아니라, 사전 지식이나 믿음을 활용하여 추정의 정확도를 높이는 방법이 필요했습니다.
베이즈 정리와 최대 우도 추정은 확률론과 통계학의 핵심 개념으로, 딥러닝에서 모델 학습과 추론에 광범위하게 적용됩니다.
베이즈 정리는 조건부 확률을 계산하는 방법을 제공합니다. 이는 새로운 증거가 주어졌을 때 가설의 확률을 갱신하는 데 사용됩니다. 베이즈 정리의 수학적 표현은 다음과 같습니다.
\[P(A|B) = \frac{P(B|A)P(A)}{P(B)}\]
여기서: - \(P(A|B)\)는 B가 주어졌을 때 A의 확률 (사후 확률) - \(P(B|A)\)는 A가 주어졌을 때 B의 확률 (우도) - \(P(A)\)는 A의 확률 (사전 확률) - \(P(B)\)는 B의 확률 (증거)
베이즈 정리는 머신러닝에서 다음과 같이 활용됩니다.
최대 우도 추정(Maximum Likelihood Estimation, MLE)은 주어진 데이터를 가장 잘 설명하는 모델 파라미터를 찾는 방법입니다. 딥러닝의 맥락에서, 이는 신경망이 관측된 데이터를 가장 잘 설명할 수 있는 가중치와 편향을 찾는 과정을 의미합니다. 즉, 최대 우도 추정은 모델이 훈련 데이터를 생성할 확률을 최대화하는 파라미터를 찾는 것으로, 이는 곧 모델의 학습 과정과 직접적으로 연결됩니다. 수학적으로, 데이터 \(X = (x_1, ..., x_n)\)가 주어졌을 때, 파라미터 \(\theta\)에 대한 우도 함수는 다음과 같이 정의됩니다.
\[L(\theta|X) = P(X|\theta) = \prod_{i=1}^n P(x_i|\theta)\]
최대 우도 추정치 \(\hat{\theta}_{MLE}\)는 다음과 같이 구합니다.
\[\hat{\theta}_{MLE} = \operatorname{argmax}_{\theta} L(\theta|X)\]
실제로는 로그 우도를 최대화하는 것이 계산상 더 편리합니다.
\[\hat{\theta}_{MLE} = \operatorname{argmax}_{\theta} \log L(\theta|X) = \operatorname{argmax}_{\theta} \sum_{i=1}^n \log P(x_i|\theta)\]
로그 우도를 사용하는 데에는 여러 가지 중요한 수학적 장점이 있습니다.
이러한 이유로, 딥러닝을 포함한 많은 기계학습 알고리즘에서는 로그 우도를 사용하여 최적화를 수행합니다.
최대 우도 추정은 딥러닝에서 다음과 같이 활용됩니다.
베이즈 정리와 최대 우도 추정은 서로 밀접한 관련이 있습니다. 베이즈 추정에서 사전 확률이 균일 분포일 경우, 최대 사후 확률(MAP) 추정은 최대 우도 추정과 동일해집니다. 수학적으로 표현하면, \(P(\theta|X) \propto P(X|\theta)P(\theta)\)에서 \(P(\theta)\)가 상수일 때, \(\operatorname{argmax}_{\theta} P(\theta|X) = \operatorname{argmax}_{\theta} P(X|\theta)P(\theta)\)가 됩니다. 이는 사전 확률이 파라미터에 대한 추가적인 정보를 제공하지 않을 때, 데이터만을 기반으로 한 추정(MLE)이 베이즈 추정(MAP)과 일치함을 의미합니다.
이러한 개념들은 딥러닝 모델의 학습과 추론 과정을 이해하고 최적화하는 데 필수적입니다. 다음 섹션에서는 정보 이론의 기초에 대해 알아보겠습니다.
MLE는 주어진 데이터를 가장 잘 설명하는 모수(parameter)를 찾는 방법입니다. 관측된 데이터의 가능도(likelihood)를 최대화하는 모수 값을 찾는 것입니다.
가능도 함수 (Likelihood Function):
로그 가능도 함수 (Log-Likelihood Function):
MLE 계산 절차:
구체적인 예시:
MAP: 베이즈 정리를 기반으로, 사전 확률(prior probability)과 가능도(likelihood)를 결합하여 사후 확률(posterior probability)을 최대화하는 모수를 찾는 방법입니다.
MAP 추정: \[ \hat{\theta}_{MAP} = \arg\max_{\theta} p(\theta|x) = \arg\max_{\theta} \frac{p(x|\theta)p(\theta)}{p(x)} = \arg\max_{\theta} p(x|\theta)p(\theta) \]
MLE vs. MAP:
| 특징 | MLE | MAP |
|---|---|---|
| 기반 | 빈도주의 (Frequentist) | 베이지안 (Bayesian) |
| 목표 | 가능도 최대화 | 사후 확률 최대화 |
| 사전 확률 | 고려하지 않음 | 고려함 |
| 결과 | 점 추정 (Point Estimate) | 점 추정 (일반적으로) 또는 분포 추정 (베이지안 추론의 경우) |
| 과적합 | 과적합 가능성 높음 | 사전 확률을 통해 과적합 방지 가능 (e.g., Regularization 효과) |
| 계산 복잡도 | 일반적으로 낮음 | 사전 확률에 따라 복잡도가 증가할 수 있음 (특히, 켤레 사전 분포가 아닌 경우) |
도전과제: 어떻게 정보의 양을 측정하고, 불확실성을 정량화할 수 있을까?
연구자의 고뇌: 클로드 섀넌은 통신 시스템에서 정보의 효율적인 전송과 압축에 대한 근본적인 질문에 직면했습니다. 정보를 정량화하고, 정보의 손실 없이 데이터를 얼마나 압축할 수 있는지, 그리고 노이즈가 있는 채널을 통해 얼마나 많은 정보를 안정적으로 전송할 수 있는지에 대한 이론적 근거가 필요했습니다.
정보 이론은 데이터의 압축, 전송, 저장에 관한 수학적 이론으로, 딥러닝에서 모델의 성능 평가와 최적화에 중요한 역할을 합니다. 이 섹션에서는 정보 이론의 핵심 개념인 엔트로피, 상호 정보량, KL 발산에 대해 알아보겠습니다.
엔트로피는 정보의 불확실성을 측정하는 척도입니다. 확률 분포 P에 대한 엔트로피 H(P)는 다음과 같이 정의됩니다.
\[H(P) = -\sum_{x} P(x) \log P(x)\]
여기서 x는 가능한 모든 사건을 나타냅니다. 엔트로피의 주요 특성은 다음과 같습니다.
딥러닝에서 엔트로피는 주로 분류 문제의 손실 함수로 사용되는 교차 엔트로피의 기반이 됩니다. 다음 예제는 다양한 확률 분포의 엔트로피를 계산하고, 이진 분포의 엔트로피를 시각화합니다.
from dldna.chapter_02.information_theory import calculate_entropy
calculate_entropy()Entropy of fair coin: 0.69
Entropy of biased coin: 0.33
Entropy of fair die: 1.39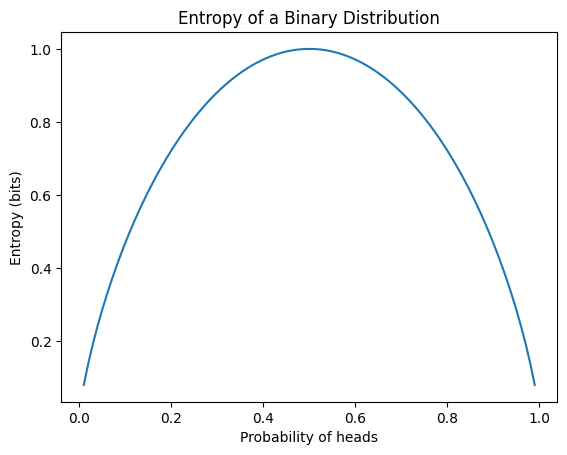
상호 정보량(Mutual Information)은 두 확률 변수 X와 Y 사이의 상호 의존성을 측정합니다. 수학적으로 다음과 같이 정의됩니다.
\[I(X;Y) = \sum_{x}\sum_{y} P(x,y) \log \frac{P(x,y)}{P(x)P(y)}\]
상호 정보량의 주요 특성은 다음과 같습니다.
상호 정보량은 특징 선택, 차원 축소 등 다양한 머신러닝 작업에서 활용됩니다. 다음 예제는 간단한 결합 확률 분포에 대한 상호 정보량을 계산하고 시각화합니다.
from dldna.chapter_02.information_theory import mutual_information_example
mutual_information_example()Mutual Information: 0.0058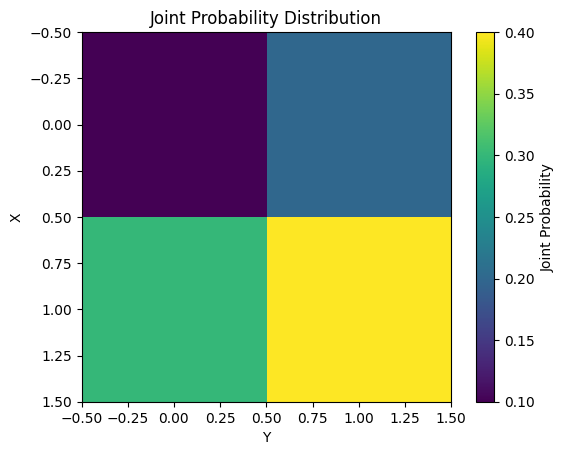
KL(Kullback-Leibler) 발산은 두 확률 분포 P와 Q의 차이를 측정하는 방법입니다. P에 대한 Q의 KL 발산은 다음과 같이 정의됩니다.
\[D_{KL}(P||Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)}\]
KL 발산의 주요 특성은 다음과 같습니다.
KL 발산은 딥러닝에서 다음과 같이 활용됩니다.
정보 이론의 개념들은 서로 밀접하게 연관되어 있습니다. 예를 들어, 상호 정보량은 엔트로피와 조건부 엔트로피의 차이로 표현할 수 있습니다.
\(I(X;Y) = H(X) - H(X|Y)\)
또한, KL 발산은 교차 엔트로피와 엔트로피의 차이로 나타낼 수 있습니다.
\(D_{KL}(P||Q) = H(P,Q) - H(P)\)
여기서 \(H(P,Q)\)는 \(P\)와 \(Q\)의 교차 엔트로피입니다. 다음은 두 확률 분포 간의 KL 발산을 계산하고 분포를 시각화합니다.
from dldna.chapter_02.information_theory import kl_divergence_example
kl_divergence_example()KL(P||Q): 0.0823
KL(Q||P): 0.0872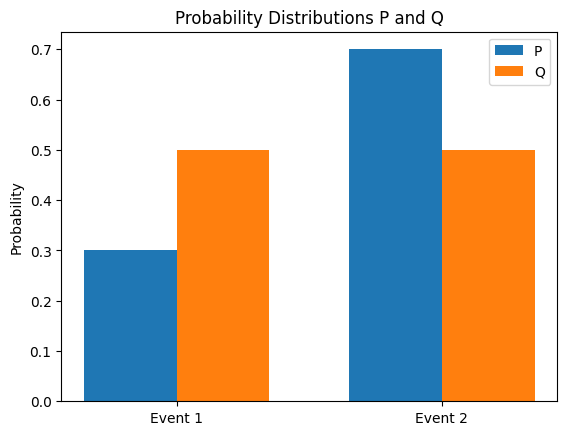
이러한 정보 이론의 개념들은 딥러닝 모델의 설계와 최적화에 광범위하게 적용됩니다. 예를 들어, 오토인코더의 손실 함수로 재구성 오차와 KL 발산의 조합을 사용하거나, 강화학습에서 정책 최적화를 위해 KL 발산을 제약 조건으로 사용하는 등 다양한 방식으로 활용됩니다.
다음 장에서는 이러한 확률, 통계, 정보 이론의 개념들이 실제 딥러닝 모델에서 어떻게 적용되는지 살펴보겠습니다.
정의: 정보량 (Information Content, Self-information)은 특정 사건이 발생했을 때 얻을 수 있는 정보의 양을 나타냅니다. 드물게 발생하는 사건일수록 더 높은 정보량을 갖습니다.
수식: \[I(x) = -\log(P(x))\]
직관적 설명:
성질:
정의: 크로스 엔트로피(Cross Entropy)는 두 확률 분포 \(P\)와 \(Q\)가 얼마나 다른지를 측정하는 척도입니다. \(P\)를 참 분포, \(Q\)를 추정 분포라고 할 때, \(Q\)를 사용하여 \(P\)를 나타낼 때 필요한 평균 비트 수를 나타냅니다.
유도:
직관적 설명:
Binary Cross Entropy (BCE):
Categorical Cross Entropy (CCE):
KL-Divergence (Kullback-Leibler Divergence):
KL-Divergence와 Cross Entropy의 관계:
\[D_{KL}(P||Q) = \sum_{x} P(x) \log P(x) - \sum_{x} P(x) \log Q(x) = -\sum_{x} P(x) \log Q(x) - (-\sum_{x} P(x) \log P(x))\] \[D_{KL}(P||Q) = H(P, Q) - H(P)\]
\(H(P,Q)\): Cross Entropy
\(H(P)\): Entropy
KL-Divergence는 Cross Entropy에서 \(P\)의 Entropy를 뺀 값입니다.
\(P\)가 고정되어 있을 때, Cross Entropy를 최소화하는 것은 KL-Divergence를 최소화하는 것과 같습니다.
Mutual Information (상호 정보량):
Conditional Entropy (조건부 엔트로피):
Mutual Information과 Conditional Entropy 관계: \[I(X;Y) = H(X) - H(X|Y) = H(Y) - H(Y|X)\]
손실 함수(Loss Function)는 머신러닝 모델의 예측이 실제 값과 얼마나 차이가 나는지를 측정하는 함수입니다. 모델 학습의 목표는 이 손실 함수의 값을 최소화하는 파라미터(가중치와 편향)를 찾는 것입니다. 적절한 손실 함수를 선택하는 것은 모델의 성능에 큰 영향을 미치므로, 문제의 유형과 데이터의 특성에 맞게 신중하게 선택해야 합니다.
일반적으로 손실 함수 \(L\)은 모델의 파라미터를 \(\theta\), 데이터 포인트를 \((x_i, y_i)\)라고 할 때, 다음과 같이 표현할 수 있습니다. (여기서 \(y_i\)는 실제 값, \(f(x_i; \theta)\)는 모델의 예측값)
\(L(\theta) = \frac{1}{N} \sum_{i=1}^{N} l(y_i, f(x_i; \theta))\)
\(N\)은 데이터 포인트의 개수, \(l\)은 개별 데이터 포인트에 대한 손실을 나타내는 함수(loss term)입니다.
다음은 머신러닝과 딥러닝에서 자주 사용되는 손실 함수들입니다.
많은 머신러닝 모델의 학습은 최대 우도 추정(MLE) 관점에서 설명할 수 있습니다. MLE는 주어진 데이터를 가장 잘 설명하는 모델 파라미터를 찾는 방법입니다. 데이터가 독립적이고 동일한 분포(i.i.d)를 따른다고 가정할 때, 우도 함수(Likelihood Function)는 다음과 같이 정의됩니다.
\(L(\theta) = P(D|\theta) = \prod_{i=1}^{N} P(y_i | x_i; \theta)\)
여기서 \(D = \{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\}\)는 훈련 데이터, \(\theta\)는 모델 파라미터입니다. \(P(y_i | x_i; \theta)\)는 모델이 \(x_i\)를 입력으로 받았을 때 \(y_i\)를 출력할 확률(또는 확률 밀도)입니다.
MLE의 목표는 우도 함수 \(L(\theta)\)를 최대화하는 파라미터 \(\theta\)를 찾는 것입니다. 실제로는 로그 우도 함수(log-likelihood function)를 최대화하는 것이 계산상 더 편리합니다.
\(\log L(\theta) = \sum_{i=1}^{N} \log P(y_i | x_i; \theta)\)
MSE와 MLE: 선형 회귀 모델에서 오차가 평균이 0이고 분산이 \(\sigma^2\)인 정규 분포를 따른다고 가정하면, MLE는 MSE를 최소화하는 것과 동일합니다.
\(P(y_i | x_i; \theta) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - f(x_i; \theta))^2}{2\sigma^2}\right)\)
로그 우도 함수는 다음과 같습니다. \(\log L(\theta) = -\frac{N}{2}\log(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^{N}(y_i - f(x_i;\theta))^2\)
상수를 제외하고, \(\sigma^2\)이 상수라고 가정하면 로그 우도 함수를 최대화하는 것은 MSE를 최소화하는 것과 같습니다.
Cross-Entropy와 MLE: 분류 문제에서, 출력 \(\hat{y}_i\)를 베르누이 분포(이진 분류) 또는 다항 분포(다중 클래스 분류)의 파라미터로 해석할 수 있습니다. 이 경우, MLE는 Cross-Entropy Loss를 최소화하는 것과 동일합니다.
이진 분류 (베르누이 분포): \(\hat{y_i}\)를 모델이 예측한, \(y_i=1\)일 확률이라고 하면, \(P(y_i|x_i;\theta) = \hat{y_i}^{y_i} (1 - \hat{y_i})^{(1-y_i)}\) 로그 우도: \(\log L(\theta) = \sum_{i=1}^{N} [y_i \log(\hat{y}_i) + (1 - y_i)\log(1 - \hat{y}_i)]\)
다중 클래스 분류 (Categorical/Multinoulli Distribution): \(P(y_i | x_i; \theta) = \prod_{j=1}^{C} \hat{y}_{ij}^{y_{ij}}\) (one-hot encoding) 로그 우도: \(\log L(\theta) = \sum_{i=1}^N \sum_{j=1}^C y_{ij} \log(\hat{y}_{ij})\)
따라서 Cross-Entropy Loss를 최소화하는 것은 데이터의 분포를 가장 잘 모델링하는 파라미터를 찾는 MLE와 동일한 과정입니다.
Kullback-Leibler Divergence (KLD):
Focal Loss:
Huber Loss: MSE와 MAE의 장점을 결합한 손실 함수입니다. 오차가 특정 값(\(\delta\))보다 작을 때는 MSE처럼 제곱 오차를 사용하고, 오차가 클 때는 MAE처럼 절댓값 오차를 사용합니다. 이상치에 강건하면서도 미분 가능합니다.
\(L_\delta(y, \hat{y}) = \begin{cases} \frac{1}{2}(y - \hat{y})^2 & \text{if } |y - \hat{y}| \le \delta \\ \delta(|y - \hat{y}| - \frac{1}{2}\delta) & \text{otherwise} \end{cases}\)
Log-Cosh Loss: \(\log(\cosh(y - \hat{y}))\)로 정의됩니다. Huber Loss와 유사하게 이상치에 강건하며, 모든 지점에서 두 번 미분 가능하다는 장점이 있습니다.
Quantile Loss: 특정 분위수(quantile)에서의 예측 오차를 최소화하는 데 사용됩니다.
Contrastive Loss, Triplet Loss: Siamese Network, Triplet Network 등에서 사용되며, 유사한 샘플 쌍/세 쌍 간의 거리를 조절하는 데 사용됩니다. (자세한 내용은 관련 논문 참고)
Connectionist Temporal Classification (CTC) Loss: 음성 인식, 필기 인식 등 입력 시퀀스와 출력 시퀀스 간의 정렬(alignment)이 명확하지 않은 경우에 사용됩니다.
손실 함수는 딥러닝 모델의 성능을 결정하는 중요한 요소 중 하나입니다. 문제의 특성과 데이터의 분포, 그리고 모델의 구조를 고려하여 적절한 손실 함수를 선택하고, 필요하다면 새로운 손실 함수를 설계하는 능력이 딥러닝 엔지니어에게 요구됩니다.
기존의 손실 함수(MSE, Cross-Entropy 등)가 항상 최적의 선택은 아닙니다. 문제의 특수한 요구 사항, 데이터의 분포, 모델의 구조 등에 따라 새로운 손실 함수를 설계해야 할 필요가 있습니다. 새로운 손실 함수를 설계하는 것은 딥러닝 연구의 중요한 부분이며, 모델의 성능을 크게 향상시킬 수 있는 잠재력을 가지고 있습니다.
새로운 손실 함수를 설계할 때는 다음 원칙들을 고려해야 합니다.
문제 정의와 목표: 해결하고자 하는 문제와 모델의 궁극적인 목표를 명확히 정의해야 합니다. 손실 함수는 모델이 무엇을 학습해야 하는지를 정의하는 핵심 요소입니다. (예: 단순히 분류 정확도를 높이는 것인지, 특정 클래스를 더 잘 맞추는 것인지, False Positive/False Negative 비율을 조절하는 것인지 등)
수학적 타당성:
해석 가능성 (Interpretability): 손실 함수의 의미를 직관적으로 이해할 수 있으면, 모델의 학습 과정을 분석하고 디버깅하는 데 도움이 됩니다. 각 항(term)이 어떤 역할을 하는지, 어떤 의미를 가지는지 명확해야 합니다. 하이퍼파라미터의 의미와 영향도 명확해야 합니다.
계산 효율성 (Computational Efficiency): 손실 함수는 매 반복(iteration)마다, 그리고 모든(또는 미니배치) 데이터 포인트에 대해 계산되므로, 계산 비용이 너무 크면 학습 속도가 느려질 수 있습니다.
기존 손실 함수 변형/결합:
확률적 모델링 기반 설계:
문제 특화 손실 함수 설계:
새로운 손실 함수를 설계하는 것은 창의적인 과정이지만, 동시에 신중한 접근이 필요합니다. 문제의 본질을 깊이 이해하고, 수학적/통계적 원리에 기반하여 설계하며, 철저한 실험을 통해 성능을 검증하는 것이 중요합니다.
이 장에서는 딥러닝의 수학적 기초를 살펴보았습니다. 선형 대수, 미적분, 확률 및 통계, 정보 이론 등 다양한 분야의 개념들이 딥러닝 모델의 설계, 학습, 분석에 어떻게 활용되는지 알아보았습니다. 이러한 수학적 도구들은 복잡한 신경망 구조를 이해하고, 효율적인 학습 알고리즘을 개발하며, 모델의 성능을 평가하고 개선하는 데 필수적입니다. 또한 딥러닝 연구의 최전선에서 새로운 돌파구를 찾는 데에도 중요한 역할을 합니다.
두 벡터 \(\mathbf{a} = \begin{bmatrix} 1 \\ 2 \end{bmatrix}\) 와 \(\mathbf{b} = \begin{bmatrix} 3 \\ 4 \end{bmatrix}\) 의 내적(dot product)을 계산하시오.
행렬 \(\mathbf{A} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}\) 와 벡터 \(\mathbf{b} = \begin{bmatrix} 5 \\ 6 \end{bmatrix}\) 의 곱 \(\mathbf{Ab}\) 를 계산하시오.
2x2 단위 행렬(identity matrix)을 생성하시오.
벡터의 L1 norm과 L2 norm의 정의를 쓰고, 벡터 \(\mathbf{v} = \begin{bmatrix} 3 \\ -4 \end{bmatrix}\) 의 L1 norm과 L2 norm을 계산하시오.
행렬 \(\mathbf{A} = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix}\) 의 고유값(eigenvalue)과 고유벡터(eigenvector)를 구하시오.
주어진 행렬의 역행렬이 존재하는지 판별하고, 존재한다면 역행렬을 계산하시오. \(\mathbf{A} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}\)
선형 변환 \(T(\mathbf{x}) = \mathbf{Ax}\) 가 주어졌을 때, 기저(basis) 벡터 \(\mathbf{e_1} = \begin{bmatrix} 1 \\ 0 \end{bmatrix}\) 와 \(\mathbf{e_2} = \begin{bmatrix} 0 \\ 1 \end{bmatrix}\) 가 어떻게 변환되는지 설명하고, 그 결과를 시각화하시오. (단, \(\mathbf{A} = \begin{bmatrix} 2 & -1 \\ 1 & 1 \end{bmatrix}\))
다음 행렬의 랭크(rank)를 계산하시오. \(\mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}\)
특이값 분해(Singular Value Decomposition, SVD)의 정의를 쓰고, 주어진 행렬 \(\mathbf{A}\) 를 SVD로 분해하시오. \(\mathbf{A} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix}\)
주성분 분석(Principal Component Analysis, PCA)의 목적과 과정을 설명하고, 주어진 데이터셋에 대해 PCA를 수행하여 1차원으로 차원을 축소하시오.
import numpy as np
data = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])다음 행렬의 영공간(null space)과 열공간(column space)의 기저(basis)를 구하시오. \(\mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}\)
QR 분해의 정의를 쓰고, 주어진 행렬 \(\mathbf{A}\) 를 QR 분해하시오. (QR 분해는 수치적으로 안정적인 방법으로, 선형 방정식의 해를 구하거나, 고유값 문제를 해결하는 데 사용됩니다.) \(\mathbf{A} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}\)
내적 계산: \(\mathbf{a} \cdot \mathbf{b} = (1)(3) + (2)(4) = 3 + 8 = 11\)
행렬-벡터 곱: \(\mathbf{Ab} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} \begin{bmatrix} 5 \\ 6 \end{bmatrix} = \begin{bmatrix} (1)(5) + (2)(6) \\ (3)(5) + (4)(6) \end{bmatrix} = \begin{bmatrix} 17 \\ 39 \end{bmatrix}\)
2x2 단위 행렬: \(\mathbf{I} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}\)
L1, L2 Norm:
\(\mathbf{v} = \begin{bmatrix} 3 \\ -4 \end{bmatrix}\) \(||\mathbf{v}||_1 = |3| + |-4| = 3 + 4 = 7\) \(||\mathbf{v}||_2 = \sqrt{(3)^2 + (-4)^2} = \sqrt{9 + 16} = \sqrt{25} = 5\)
고유값, 고유벡터: \(\mathbf{A} = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix}\)
특성 방정식: \(\det(\mathbf{A} - \lambda\mathbf{I}) = 0\) \((2-\lambda)^2 - (1)(1) = 0\) \(\lambda^2 - 4\lambda + 3 = 0\) \((\lambda - 3)(\lambda - 1) = 0\) \(\lambda_1 = 3\), \(\lambda_2 = 1\)
고유벡터 (λ = 3): \((\mathbf{A} - 3\mathbf{I})\mathbf{v} = 0\) \(\begin{bmatrix} -1 & 1 \\ 1 & -1 \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}\) \(x = y\), \(\mathbf{v_1} = \begin{bmatrix} 1 \\ 1 \end{bmatrix}\) (또는 임의의 상수배)
고유벡터 (λ = 1): \((\mathbf{A} - \mathbf{I})\mathbf{v} = 0\) \(\begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}\) \(x = -y\), \(\mathbf{v_2} = \begin{bmatrix} -1 \\ 1 \end{bmatrix}\) (또는 임의의 상수배)
역행렬: \(\mathbf{A} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}\)
선형 변환 시각화:
랭크 계산: \(\mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}\) 행 사다리꼴 형태로 변환하면, 두 개의 행이 0이 아닌 값을 가지므로 랭크는 2입니다. (세 번째 행은 첫 번째 행과 두 번째 행의 선형 조합으로 표현 가능)
SVD: \(\mathbf{A} = \mathbf{U\Sigma V^T}\)
(계산 과정은 생략. NumPy 등의 라이브러리를 사용하여 계산 가능: U, S, V = np.linalg.svd(A))
PCA:
import numpy as np
data = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
# 1. 데이터 중심화 (평균 빼기)
mean = np.mean(data, axis=0)
centered_data = data - mean
# 2. 공분산 행렬 계산
covariance_matrix = np.cov(centered_data.T)
# 3. 고유값, 고유벡터 계산
eigenvalues, eigenvectors = np.linalg.eig(covariance_matrix)
# 4. 주성분 선택 (가장 큰 고유값에 해당하는 고유벡터)
# 고유값을 내림차순으로 정렬하고, 가장 큰 고유값에 해당하는 고유벡터 선택
sorted_indices = np.argsort(eigenvalues)[::-1] # 내림차순 정렬 인덱스
largest_eigenvector = eigenvectors[:, sorted_indices[0]]
# 5. 1차원으로 투영
projected_data = centered_data.dot(largest_eigenvector)
print(projected_data)영공간, 열공간 기저: \(\mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}\)
영공간 (Null Space): \(\mathbf{Ax} = 0\) 을 만족하는 \(\mathbf{x}\) 를 찾는 것. 행 사다리꼴 형태로 변환하여 해를 구하면, \(\mathbf{x} = t\begin{bmatrix} 1 \\ -2 \\ 1 \end{bmatrix}\) (t는 임의의 상수) 형태. 따라서 영공간의 기저는 \(\begin{bmatrix} 1 \\ -2 \\ 1 \end{bmatrix}\)
열공간 (Column Space): 행렬 \(\mathbf{A}\) 의 열벡터들의 선형 조합으로 생성되는 공간. 행 사다리꼴 형태에서 pivot column에 해당하는 원래 행렬의 열벡터들이 기저가 됨. \(\begin{bmatrix} 1 \\ 4 \\ 7 \end{bmatrix}\), \(\begin{bmatrix} 2 \\ 5 \\ 8 \end{bmatrix}\)
QR 분해: \(\mathbf{A} = \mathbf{QR}\)
(계산 과정은 Gram-Schmidt 직교화 과정을 사용하거나, NumPy 등의 라이브러리를 사용하여 계산: Q, R = np.linalg.qr(A))
함수 \(f(x) = x^3 - 6x^2 + 9x + 1\) 의 도함수 \(f'(x)\) 를 구하시오.
함수 \(f(x, y) = x^2y + 2xy^2\) 의 편미분 \(\frac{\partial f}{\partial x}\) 와 \(\frac{\partial f}{\partial y}\) 를 구하시오.
함수 \(f(x) = \sin(x^2)\) 의 도함수 \(f'(x)\) 를 체인 룰을 사용하여 구하시오.
함수 \(f(x, y) = e^{x^2 + y^2}\) 의 그래디언트 \(\nabla f\) 를 구하고, 점 (1, 1) 에서의 그래디언트 값을 계산하시오.
함수 \(f(x) = x^4 - 4x^3 + 4x^2\) 의 임계점(critical point)을 모두 찾고, 각 임계점이 극댓값, 극솟값, 또는 안장점(saddle point)인지 판별하시오.
다음 함수의 야코비안 행렬을 구하시오. \(f(x, y) = \begin{bmatrix} x^2 + y^2 \\ 2xy \end{bmatrix}\)
라그랑주 승수법(Lagrange multiplier method)을 사용하여, 제약 조건 \(g(x, y) = x^2 + y^2 - 1 = 0\) 하에서 함수 \(f(x, y) = xy\) 의 최댓값과 최솟값을 구하시오.
경사 하강법(Gradient Descent)을 사용하여 함수 \(f(x) = x^4 - 4x^3 + 4x^2\) 의 최솟값을 찾으시오. (초기값 \(x_0 = 3\), 학습률 \(\alpha = 0.01\), 반복 횟수 100회)
함수 \(f(\mathbf{x}) = \mathbf{x}^T \mathbf{A} \mathbf{x}\) 의 그래디언트 \(\nabla f\) 를 \(\mathbf{A}\) 와 \(\mathbf{x}\) 를 사용하여 나타내시오. (단, \(\mathbf{A}\) 는 대칭 행렬)
뉴턴 방법(Newton’s method)을 사용하여 방정식 \(x^3 - 2x - 5 = 0\) 의 근을 찾으시오.
도함수: \(f(x) = x^3 - 6x^2 + 9x + 1\) \(f'(x) = 3x^2 - 12x + 9\)
편미분: \(f(x, y) = x^2y + 2xy^2\) \(\frac{\partial f}{\partial x} = 2xy + 2y^2\) \(\frac{\partial f}{\partial y} = x^2 + 4xy\)
체인 룰: \(f(x) = \sin(x^2)\) \(f'(x) = \cos(x^2) \cdot (2x) = 2x\cos(x^2)\)
그래디언트: \(f(x, y) = e^{x^2 + y^2}\) \(\nabla f = \begin{bmatrix} \frac{\partial f}{\partial x} \\ \frac{\partial f}{\partial y} \end{bmatrix} = \begin{bmatrix} 2xe^{x^2 + y^2} \\ 2ye^{x^2 + y^2} \end{bmatrix}\) \(\nabla f(1, 1) = \begin{bmatrix} 2e^2 \\ 2e^2 \end{bmatrix}\)
임계점, 극값 판별: \(f(x) = x^4 - 4x^3 + 4x^2\) \(f'(x) = 4x^3 - 12x^2 + 8x = 4x(x-1)(x-2)\) 임계점: \(x = 0, 1, 2\)
\(f''(x) = 12x^2 - 24x + 8\)
야코비안 행렬: \(f(x, y) = \begin{bmatrix} x^2 + y^2 \\ 2xy \end{bmatrix}\) \(\mathbf{J} = \begin{bmatrix} \frac{\partial f_1}{\partial x} & \frac{\partial f_1}{\partial y} \\ \frac{\partial f_2}{\partial x} & \frac{\partial f_2}{\partial y} \end{bmatrix} = \begin{bmatrix} 2x & 2y \\ 2y & 2x \end{bmatrix}\)
라그랑주 승수법: \(L(x, y, \lambda) = xy - \lambda(x^2 + y^2 - 1)\) \(\frac{\partial L}{\partial x} = y - 2\lambda x = 0\) \(\frac{\partial L}{\partial y} = x - 2\lambda y = 0\) \(\frac{\partial L}{\partial \lambda} = x^2 + y^2 - 1 = 0\)
경사 하강법:
def gradient_descent(f, df, x0, alpha, iterations):
x = x0
for i in range(iterations):
x = x - alpha * df(x)
return x
f = lambda x: x**4 - 4*x**3 + 4*x**2
df = lambda x: 4*x**3 - 12*x**2 + 8*x
x_min = gradient_descent(f, df, 3, 0.01, 100)
print(x_min) # 대략 2에 수렴그래디언트 (행렬 형태): \(f(\mathbf{x}) = \mathbf{x}^T \mathbf{A} \mathbf{x}\) \(\nabla f = (\mathbf{A} + \mathbf{A}^T)\mathbf{x}\). \(\mathbf{A}\) 가 대칭 행렬이므로, \(\nabla f = 2\mathbf{A}\mathbf{x}\)
뉴턴 방법: \(f(x) = x^3 - 2x - 5\) \(f'(x) = 3x^2 - 2\) \(x_{n+1} = x_n - \frac{f(x_n)}{f'(x_n)}\)
def newton_method(f, df, x0, iterations):
x = x0
for i in range(iterations):
x = x - f(x) / df(x)
return x
f = lambda x: x**3 - 2*x - 5
df = lambda x: 3*x**2 - 2
root = newton_method(f, df, 2, 5) # 초기값 x0 = 2, 5회 반복
print(root)동전을 세 번 던졌을 때, 앞면이 두 번 나올 확률을 계산하시오.
주사위를 던졌을 때, 짝수가 나올 확률을 계산하시오.
정규 분포의 확률 밀도 함수(PDF)를 쓰고, 평균과 분산의 의미를 설명하시오.
베이즈 정리(Bayes’ theorem)를 설명하고, 다음 문제에 적용하시오.
최대 우도 추정(Maximum Likelihood Estimation, MLE)의 개념을 설명하고, 동전을 5번 던져서 앞면이 3번 나왔을 때, 동전의 앞면이 나올 확률에 대한 MLE를 구하시오.
기댓값(expectation)의 정의를 쓰고, 이산 확률 변수와 연속 확률 변수에 대한 기댓값 계산 공식을 각각 쓰시오.
엔트로피(entropy)의 정의를 쓰고, 다음 확률 분포의 엔트로피를 계산하시오.
두 확률 변수 X와 Y의 결합 확률 분포(joint probability distribution)가 다음과 같을 때, 상호 정보량(mutual information) I(X;Y)를 계산하시오.
P(X=0, Y=0) = 0.1, P(X=0, Y=1) = 0.2
P(X=1, Y=0) = 0.3, P(X=1, Y=1) = 0.4두 확률 분포 P와 Q가 다음과 같을 때, KL 발산(Kullback-Leibler divergence) \(D_{KL}(P||Q)\)를 계산하시오.
푸아송 분포(Poisson distribution)의 확률 질량 함수(PMF)를 쓰고, 어떤 경우에 사용되는지 예를 들어 설명하시오.
동전 던지기: 확률 = (3번 중 2번 앞면이 나오는 경우의 수) * (앞면 확률)^2 * (뒷면 확률)^1 = 3C2 * (1/2)^2 * (1/2)^1 = 3 * (1/4) * (1/2) = 3/8
주사위 던지기: 확률 = (짝수가 나오는 경우의 수) / (전체 경우의 수) = 3 / 6 = 1/2
정규 분포: \(f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\)
베이즈 정리: \(P(A|B) = \frac{P(B|A)P(A)}{P(B)}\)
\(P(A|B) = \frac{(0.99)(0.01)}{0.0198} = 0.5\) (50%)
최대 우도 추정 (MLE):
엔트로피:
\(H(P) = -(0.5 \log 0.5 + 0.25 \log 0.25 + 0.25 \log 0.25)\) (밑이 2인 로그를 사용하면) \(H(P) \approx 1.5\) bits
상호 정보량: \(I(X;Y) = \sum_{x}\sum_{y} P(x,y) \log \frac{P(x,y)}{P(x)P(y)}\)
\(I(X;Y) = (0.1)\log\frac{0.1}{(0.3)(0.4)} + (0.2)\log\frac{0.2}{(0.3)(0.6)} + (0.3)\log\frac{0.3}{(0.7)(0.4)} + (0.4)\log\frac{0.4}{(0.7)(0.6)}\) \(I(X;Y) \approx 0.0867\) (밑이 2인 로그 사용)
KL 발산: \(D_{KL}(P||Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)}\)
\(D_{KL}(P||Q) = 0.6 \log \frac{0.6}{0.8} + 0.4 \log \frac{0.4}{0.2} \approx 0.083\)
푸아송 분포: